短链接服务Octopus的实现与源码开放
一直想实现一个私有化的短链接服务,后来发现了这个项目,避免了重复造轮子。
前提
半年前(2020-06)左右,疫情触底反弹,公司的业务量不断提升,运营部门为了方便短信、模板消息推送等渠道的投放,提出了一个把长链接压缩为短链接的功能需求。当时为了快速推广,使用了一些比较知名的第三方短链压缩平台,存在一些问题:
- 收费贵
- 一些情况下,短链域名在部分第三方平台例如微信会被封杀
- 回源数据没有办法定制处理方案,无法打通整个业务链路进行数据分析和跟踪
基于此类问题,决定自研一个(长链接压缩为)短链接服务,当时刚好同步进行微服务拆分,内部很多微服务需要重新命名,组内的一个妹子说不如就用Github的吉祥物去命名octopus cat(章鱼猫)去命名,但是考虑到版权问题,去掉了她最喜欢的猫,剩下章鱼,以octopus命名:
(项目的描述还打错字了,应该是”短链接”)因为实现的功能并不复杂,初版于2020-06月底就发布。octopus的实现参考了互联网中几篇关于”短链服务实现”浏览量比较高的文章,下面从实现原理、服务实现和部署架构等方面展开谈谈。
基本原理
短链服务的核心就是构建短链接和长链接的唯一映射关系,依赖到一个高性能、排列组合数量大而且破解难度大的映射标识生成算法。
构建唯一映射关系
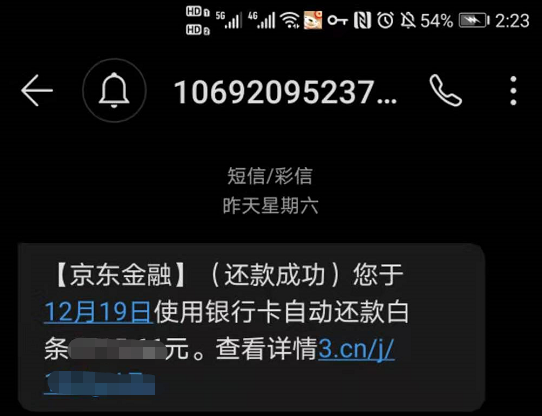
上图是笔者收到的京东白条分期还款结果提醒短信,短信内容也包含了一个短链https://3.cn/j/xxxxxxx,把它拷贝到浏览器中打开,发现客户端会重定向到长链https://jrmkt.jd.com/ptp/wl/vouchers.html?activityId=${activityId}&uep_p=${uep_p}&uep_template_id=${uep_template_id}&uep_timestamp=${uep_timestamp},然后跳入一个H5的登录页,登录后再跳进一个白条攻略页面。这里其实一个长链其实可以压成多个短链,短链可以相同域名,也可以使用不同的域名:

访问https://3.cn/j/xxxxxxx短链接具体的交互流程猜测如下:
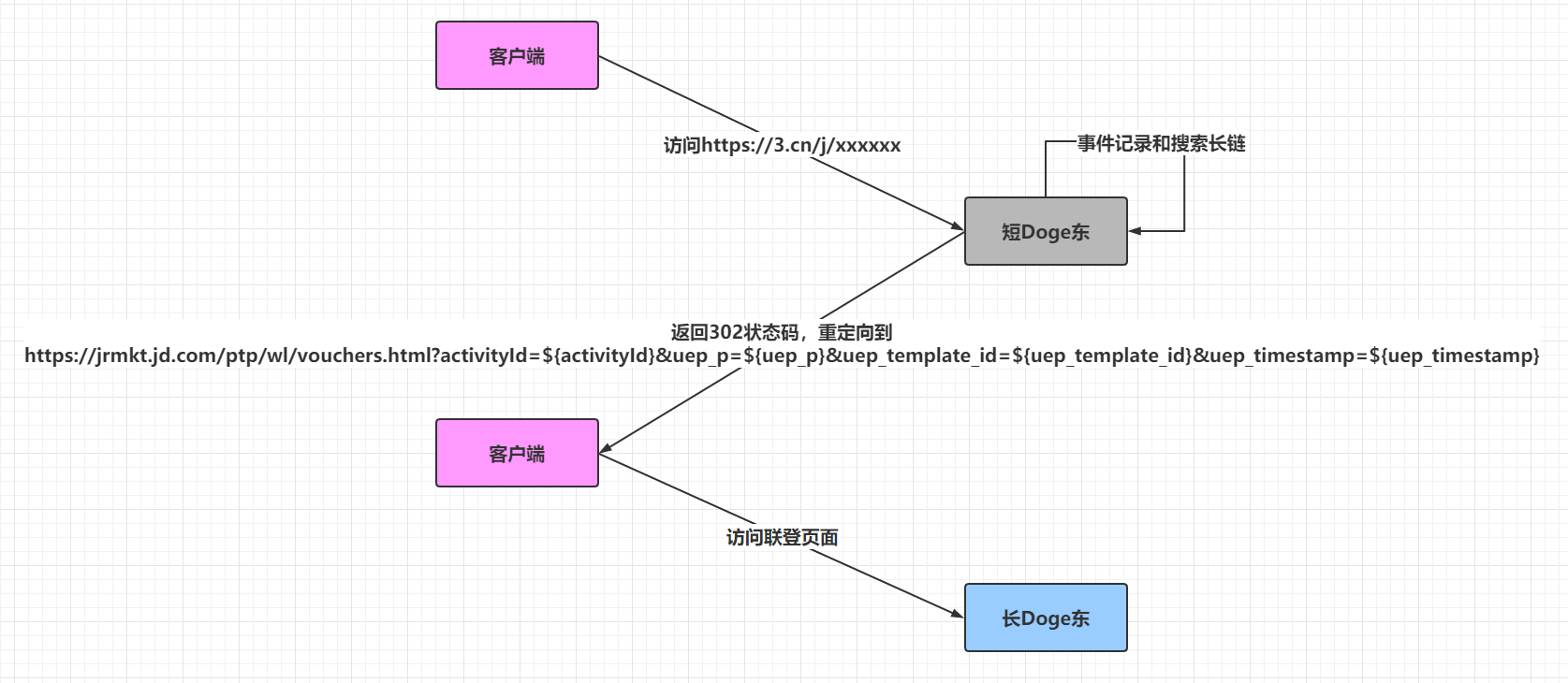
jrmkt.jd.com和3.cn查证都是doge东的域名
构建唯一映射关系其实就是基于一个固定的长链接,映射到一个或者多个可以动态生成的短链接,这个唯一映射关系,要求生成的短链接满足:
- 不容易被破解(使用数字例如数据库的自增主键作为唯一映射标识容易被人遍历出来进行恶意调用)
- 不能重复(一个短链接只能对应一个长链接,当然一个长链接可以对应多个短链接)
- 长度尽可能短,这是因为第三方推送的报文内容一般有长度限制,如果短链过长,会导致不容易传输,还会令到推送内容字数受限(试想运营商短信投放内容最大长度为
30个字符长度,短链已经占了20个字符长度,剩下只有10个字符长度让运营同事去发挥,显然不合理) - 如果链接过长,生成的二维码里面的”码点”会十分密集,不利于客户端识别和传输,刚好笔者公司运营有使用二维码的场景,所以必须尽可能缩短链接的长度
总的来说,这个唯一映射关系中的映射标识需要像Hash算法生成的Hash码那样具备高唯一性和低碰撞频率,同时具备短小易传输的特点,具体如何去生成映射唯一标识见下一节”压缩码生成算法”。
压缩码生成算法
这里的”压缩码”(compression_code)是笔者杜撰出来的名词,在本文中它的含义是短链接URL的路径部分(为了节省长度,除了协议和域名部分,短链的URL只有第一段路径):
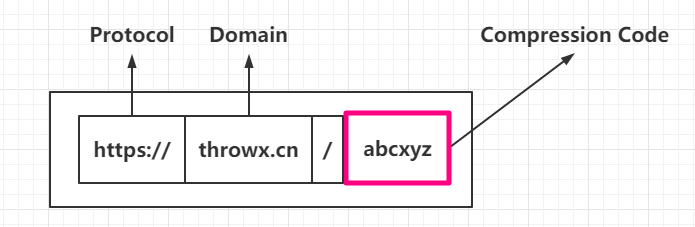
其中,协议部分基本是固定为https://(从安全性来看不建议使用http://),短链域名可以购买尽可能长度短的域名如t.cn,不过有先见之明的资本家一般会把所有优质的短域名买下并且把价格提到很高,所以域名的长度基本也是很难控制的因素,剩下可控的就是压缩码部分。压缩码部分是可控的,但因为它是URL的一部分,只要确保所使用的字符不会被URL编码转义,那么长度是人为可控的。假设我们使用的是26个字母的大小写,加上10个数字,那么对于N位压缩码可以表示的最大组合数量为:
N = 4,组合数为62 ^ 4 = 14_776_336,147万接近148万N = 5,组合数为62 ^ 5 = 916_132_832,9.16亿左右N = 6,组合数为62 ^ 6 = 56_800_235_584,568亿左右
一般来说,组合数越小破解的难度就越小,组合数越大,要求压缩码长度越大,所以常用的长度就是4、5和6,而且后期可以对失效的长链进行压缩码回收或者禁用,这三个长度对于绝大对数生产短链的应用场景都能满足。octopus在实现的时候选用的是6位长度的压缩码,无他,因为有现成的成熟的参考方案:62进制数刚好由字符0-9 a-z A-Z组成,生成压缩码的时候,只需要生成一个唯一的10进制数,然后再基于此10进制数转换为62进制数数即可。说到这里,看起来的方案如下:
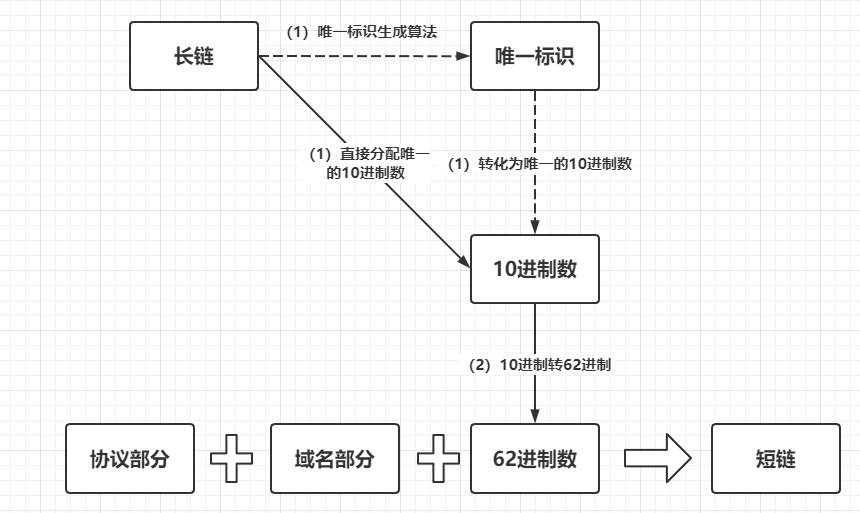
虚线部分一般依赖一种高效而且低冲突的摘要算法,如MurmurHash,而第(1)步的实线部分就是生成一个全局唯一的10进制序列,常用的手法有:
- 数据库自增序列(如自增主键)
Snowflake算法- 自研的类似
UUID算法生成全局唯一的序列值
考虑到之前笔者钻研过Snowflake算法的原理,这里简单使用Snowflake算法生成自增序列,使用了下面的流程进行压缩码生成和分配:
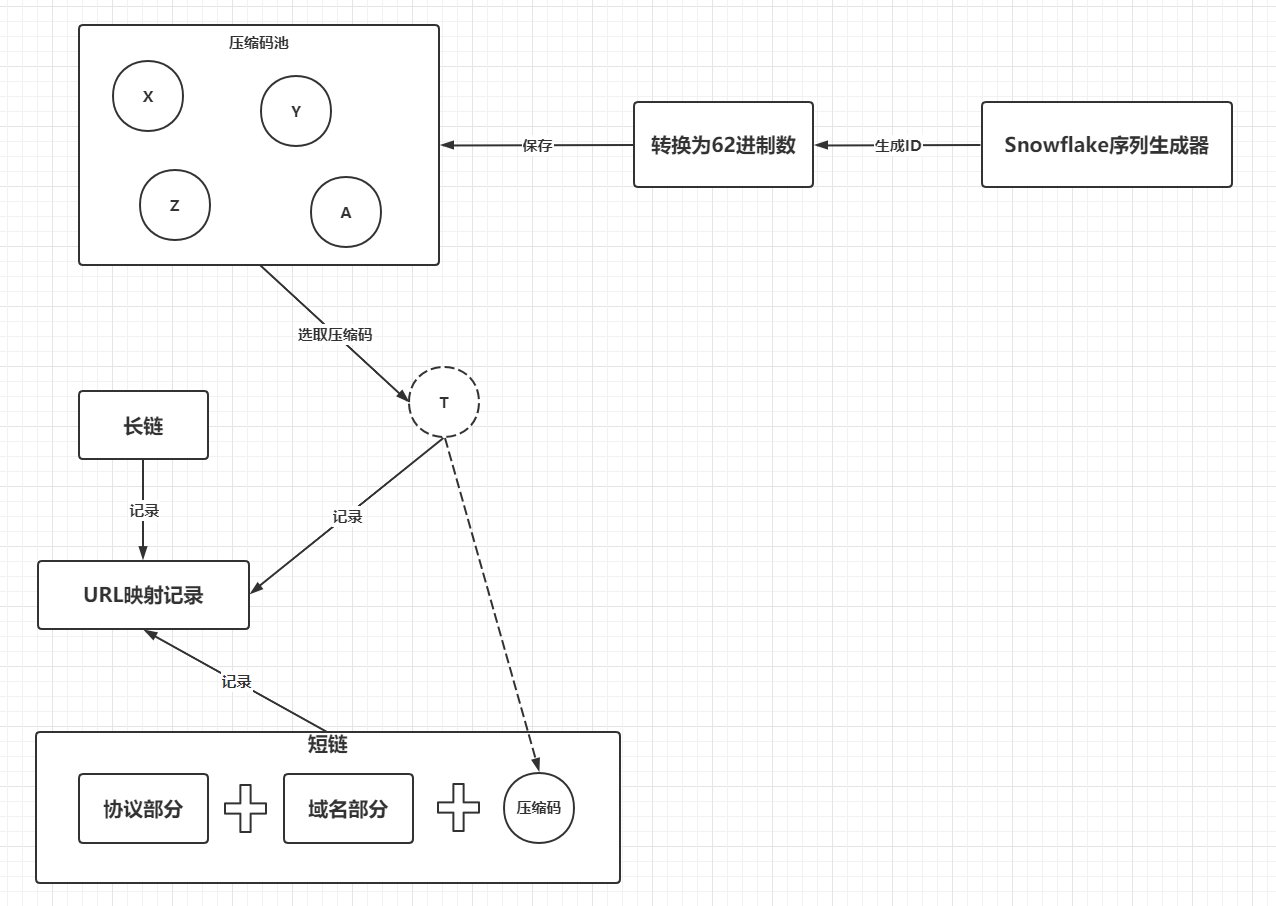
因为运用部门对短链生成的批量不大,而且短链域名只有一个,所以简单起见,一次压缩操作直接消耗掉一个压缩码,不考虑不同短链域名对同一个压缩码进行共享,也不考虑压缩码的回收问题。
服务实现
短链服务的主访问入口一般QPS极高,因此需要想尽一切办法降低该入口的耗时,考虑可以用Redis做缓存承载入口的流量,基础架构选型如下:
JDK1.8+:生产部署使用JDK11MVC框架与容器:spring-boot-starter-webflux或者spring-cloud-gateway,主要是必须使用Netty作为底层通讯容器- 内部
RPC框架:Dubbo - 服务注册与发现:
Nacos - 可选
APM工具:Pinpoint
中间件依赖(因为之前整个服务集群都上云了,低负载的服务共用了部分中间件):
MySQL8.xRedis5.x普通主从或者哨兵集群RabbitMQ3.8.x集群,使用镜像队列
服务的设计图如下:
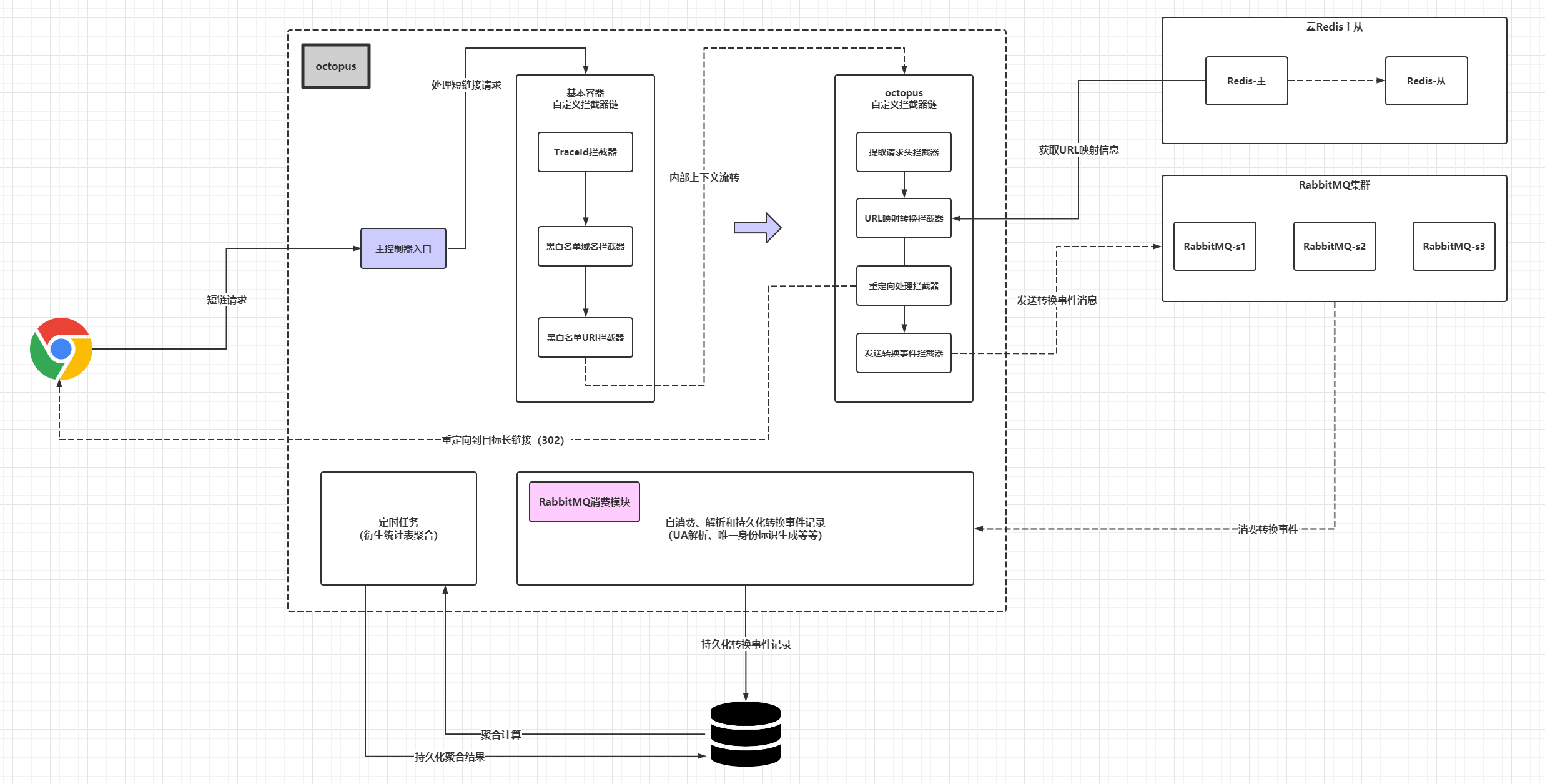
最新的版本考虑把黑白名单的拦截器去掉,替换成一个基于布隆过滤器现实的拦截器。服务使用了两个拦截器(虽然Filter翻译是过滤器,但是出于习惯,下文称为拦截器)链,容器提供的拦截器组成的拦截器链主要是负责服务安全、调用链跟踪的功能,而服务内部自定义的拦截器链主要是实现请求参数解析、URL转换、重定向和异步事件记录等功能。
模块划分:
1 | |
octopus-contract模块必须脱离父POM的管理,方便单独迭代更新。
数据库设计
一共使用了5个表:
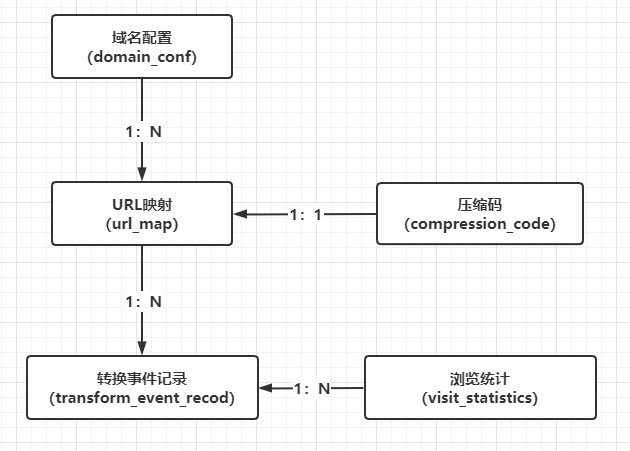
具体的初始化DDL如下:
1 | |
压缩码生成模块实现
压缩码生成的方法比较简单:
1 | |
总是批量生成可用的压缩码,查询的时候只需要查出当前未被使用的第一个压缩码即可。
容器拦截器链实现
容器的拦截器需要实现org.springframework.web.server.WebFilter(WebFlux的Filter接口),主要有四个实现(顺序如下):
MappedDiagnosticContextFilter:引入transmittable-thread-local通过MDC做TraceId的请求上下文绑定,WebFlux的线程模型和常见的Servlet容器的线程模型不一样,这里不能直接使用ThreadLocal或者Slf4j中原有的MDC实现BlockIpFilter:判断客户端请求IP是否命中黑名单AccessDomainFilter:判断域名是否命中短链域名白名单(可选的,因为外部已经通过NGINX做了一次拦截,这个实现是可有可无的)ExcludeUriFilter:判断当前请求的URI是否命中了URI黑名单
这里简单展示一下MappedDiagnosticContextFilter的实现:
1 | |
上面的TRACE_ID是配合项目的logback.xml中的pattern使用。另外需要参考https://github.com/alibaba/transmittable-thread-local/blob/master/docs/requirement-scenario.md中logback与transmittable-thread-local做集成的场景:
这里为了方便管理和升级版本,笔者直接把logback-mdc-ttl的源码实现改造好后放到项目中。
服务内部拦截器链实现
服务内部的拦截器链主要负责请求参数解析、URL映射转换、重定向和访问转换结果记录,顶层接口设计如下:
1 | |
TransformContext是一个属性承载类,本质是一个普通的JavaBean,设计如下:

目前内置了4个拦截器实现,包括:
ExtractRequestHeaderTransformFilter:请求头解析UrlTransformFilter:URL转换RedirectionTransformFilter:重定向处理TransformEventProcessTransformFilter:转换事件记录
以UrlTransformFilter为例子,源码如下:
1 | |
所有的服务内拦截器的scope都是prototype,意味着每次初始化拦截器链都会重新创建对应的Bean。
主控制器实现
因为octopus只做短链访问的入口,后台管理的功能交给另外的服务实现,此服务只有一个控制器,控制器里面只有一个方法:
1 | |
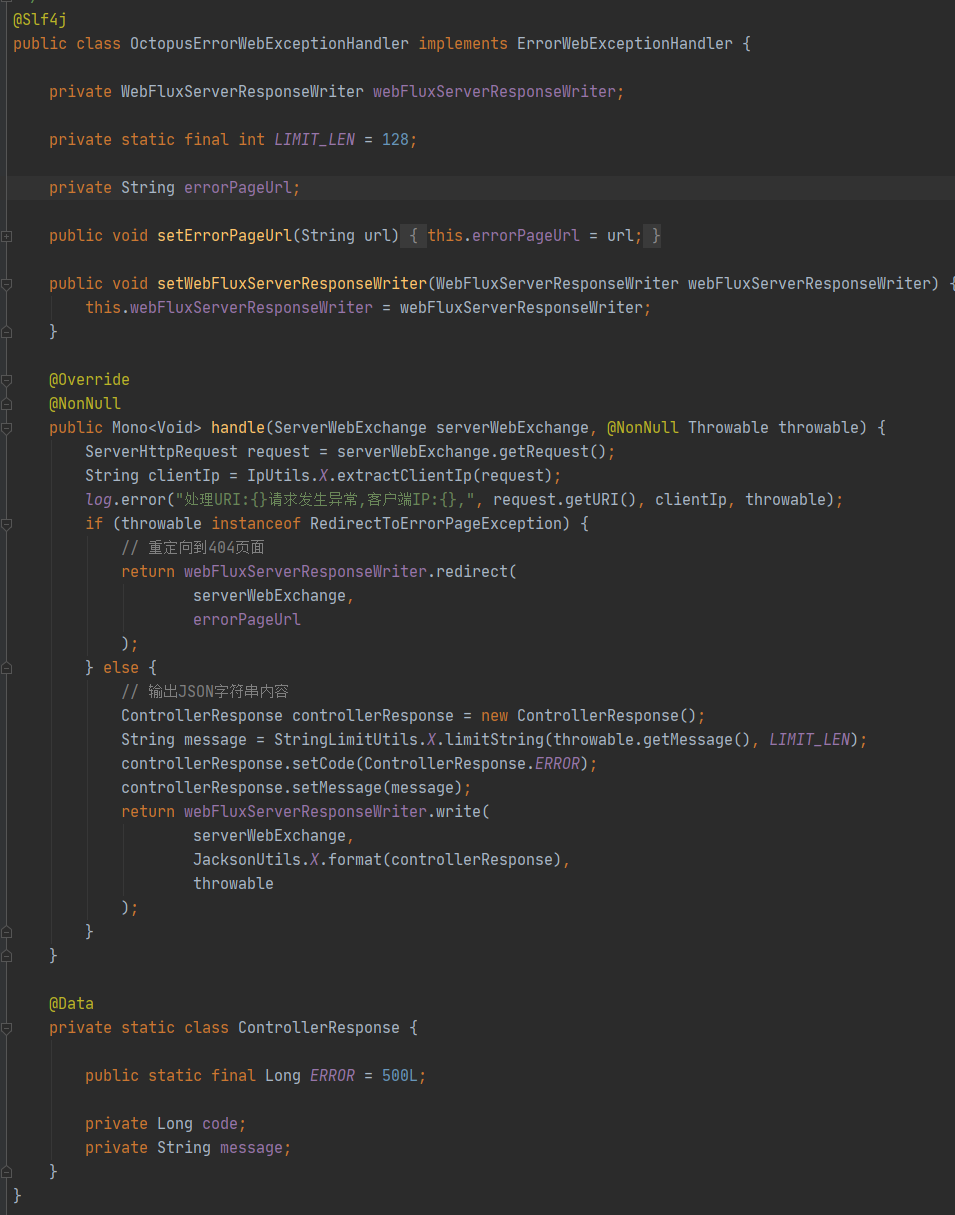
这个主控制的分发压缩码方法只负责封装参数调用服务内部拦截器链进行后续的处理。然后添加一个全局的异常处理器,把所有的异常或者非法操作引导到一个自定义的404页面(甚至可以在上面挂一点广告):
Dubbo契约实现
octopus-contract是一个完全独立的模块,甚至可以说它是一个完全独立的项目,主要作用是提供契约API,让其他服务引入,让octopus-server模块进行实现。契约接口定义如下:
1 | |
基于Dubbo的实现如下:
1 | |
生产中契约模块做了比较多的特性定制,这里只举一个简单实现的例子。
部署架构
octopus服务集群单独部署,支持无限添加节点,部署架构的关键在于网络架构,内层的负载均衡使用了Nginx,最外层的负载均衡使用了云负载均衡,如阿里云的SLB或者UCloud的ULB。添加或者移除短链域名,关键在于修改Nginx的配置。基本的架构如下:
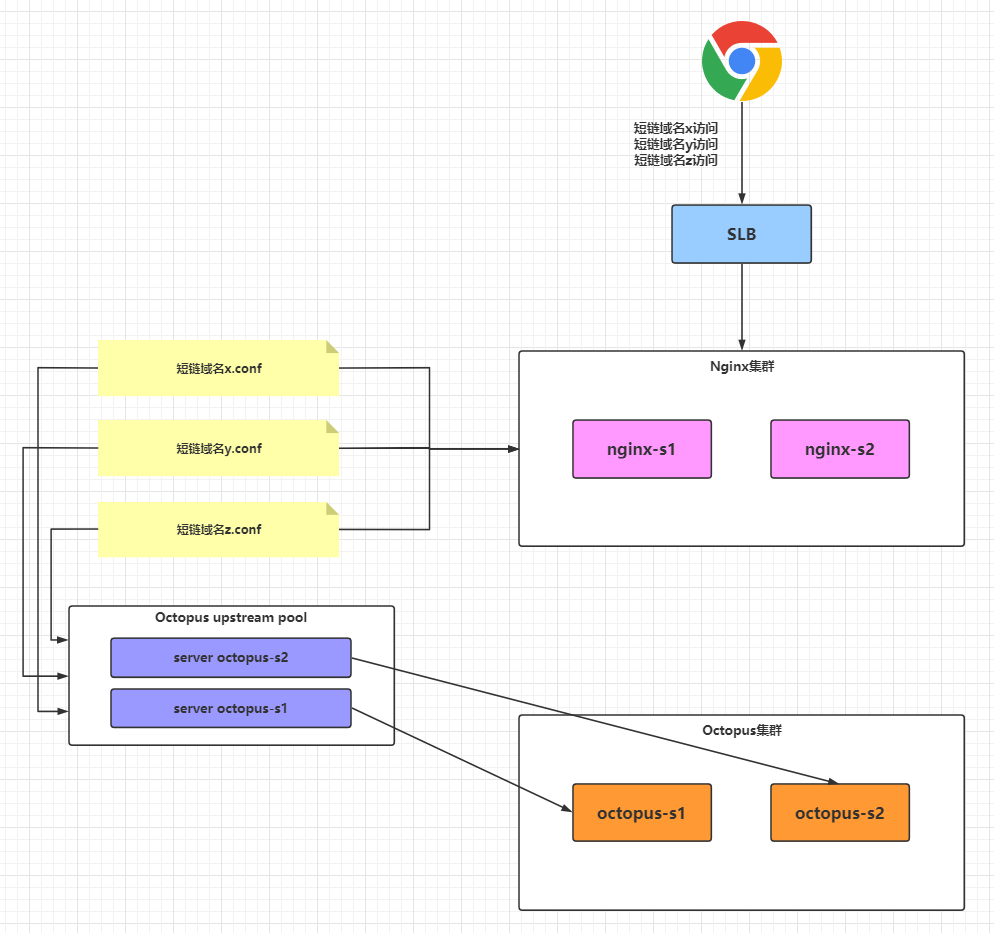
只要保证负载均衡池指向octopus集群即可,短链的域名可能动态增删,操作完之后只需要nginx -s -reload刷新一下Nginx的配置即可。
使用短链服务
先在domain_conf表写入一条本地域名和端口的数据:

编写一个集成测试类,创建一个短链映射:
1 | |
基于本地配置启动项目,然后访问http://localhost:9099/Myt8qW,效果如下:
日志如下:
1 | |
查看转换事件记录表的数据:

后续功能迭代
前期方案有一个安全隐患:没有做压缩码的白名单,容易被基于短链域名,伪造压缩码拼接短链接的方法进行攻击。解决方案是在容器的拦截器链添加或者替换一个基于布隆过滤器实现的压缩码(短链接)白名单拦截器,这样就能在前期拦截了绝大部分恶意伪造的压缩码,让极少量命中了错误率部分的恶意压缩码流到后面的处理逻辑中进行判断。另外,可以引入Caffeine配合Redis做两级缓存,毕竟本地缓存的速度更快。
小结
octopus初版是一个4小时紧急迭代出来的一个微型项目,到现在为止更新了很多次,生产上已经基本稳定。文中描述的版本是公司生产版本的移植版,精简了大量代码同时移除了一些业务耦合的设计,这里把源码开放出来,让一些有可能用到短链服务的场景提供一个可参考但尽可能不要复制的解决思路。源码仓库:
Gitee:https://gitee.com/throwableDoge/octopusGithub:https://github.com/zjcscut/octopus
代码都在main分支。
彩蛋
最近鸽了很长一段时间,原因是年底比较多业务功能迭代,内部的一个标签服务重构花了大量时间。笔者一直在摸索着通过”分片”、”异步”等等思想,在时间可控的前提下,对小数据量(百万和千万级别)前提下,通过常用的关系型数据库、缓存、消息队列等非大数据平台架构替代实现《用户画像方法论与工程化解决方案》里面提到的解决方案。

标签服务内部的代号是”千寻”,取自于辛弃疾《青玉案元夕》中的”众里寻他千百度”,项目名来自于宫崎骏的动漫《千与千寻》的女主千寻(千寻罗马音是chihiro):

待后面项目上线一段时间稳定后,应该会抽时间写一个系列谈谈怎么不用大数据那套体系,提供用户画像的工程化解决方案。
(本文完 c-10-d e-a-20201227)